MemGym
a Long-Horizon Memory Environment for LLM Agents
TL;DR — A lightweight, long-horizon evaluation gym for LLM-agent memory across coding, tool-use, computer-use, and deep-research scenarios.
Why MemGym?
Prior memory benchmarks test recall of personal facts in multi-turn chat. MemGym instead measures the memory an agent forms while it works — across coding, tool use, computer use, and deep research — where memory actually decides whether a task succeeds.
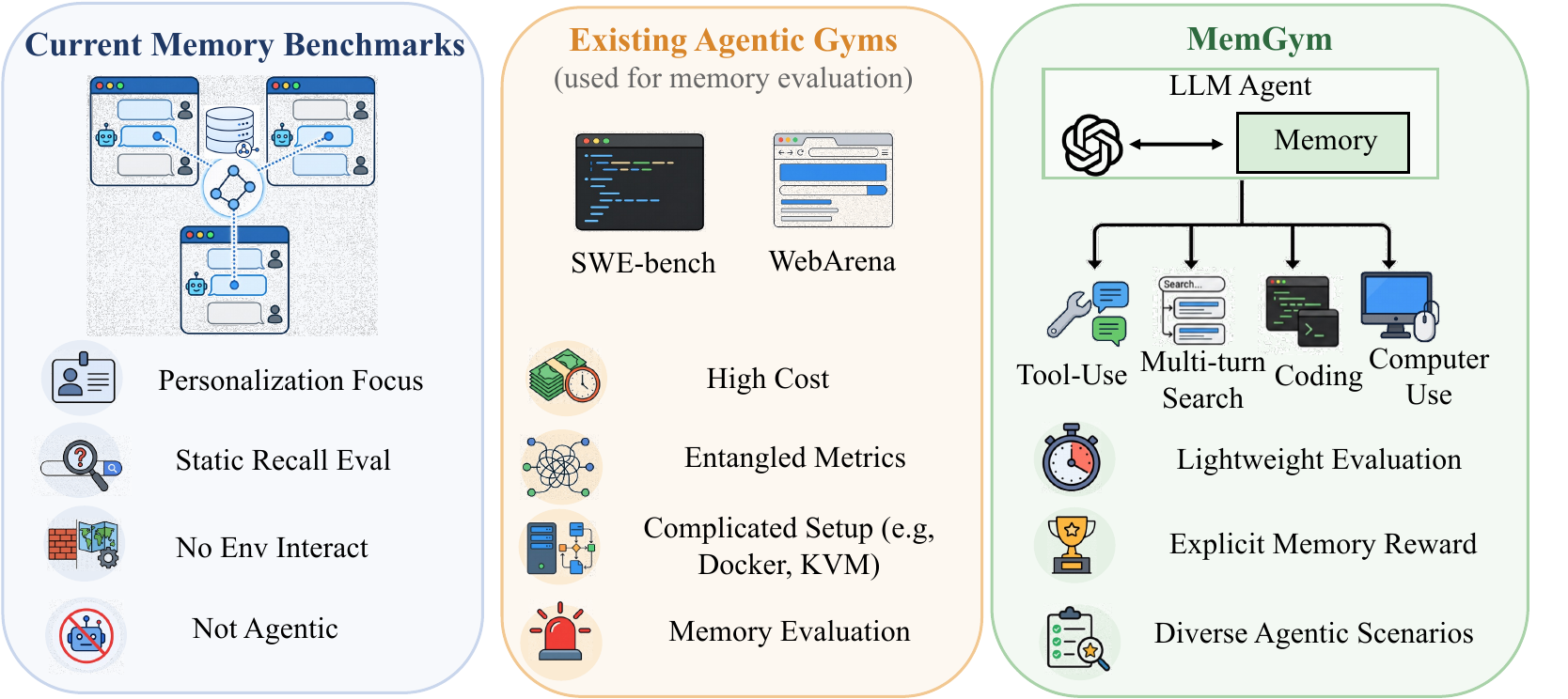
What MemGym tests
Five evaluation tracks spanning four agentic regimes. Each track pairs the best memory strategy against a same-reasoner, no-memory run, so the headline number is memory-isolated gain — not absolute task difficulty.
How it works
Every environment plugs into one memory module that wraps the prompt to the policy LLM, so a memory strategy is written once and runs everywhere — and is scored in isolation from reasoning and tool use. Recorded trajectories train MemRM, a lightweight reward model that judges whether a compression preserves the agent's behavior without re-running the agent.
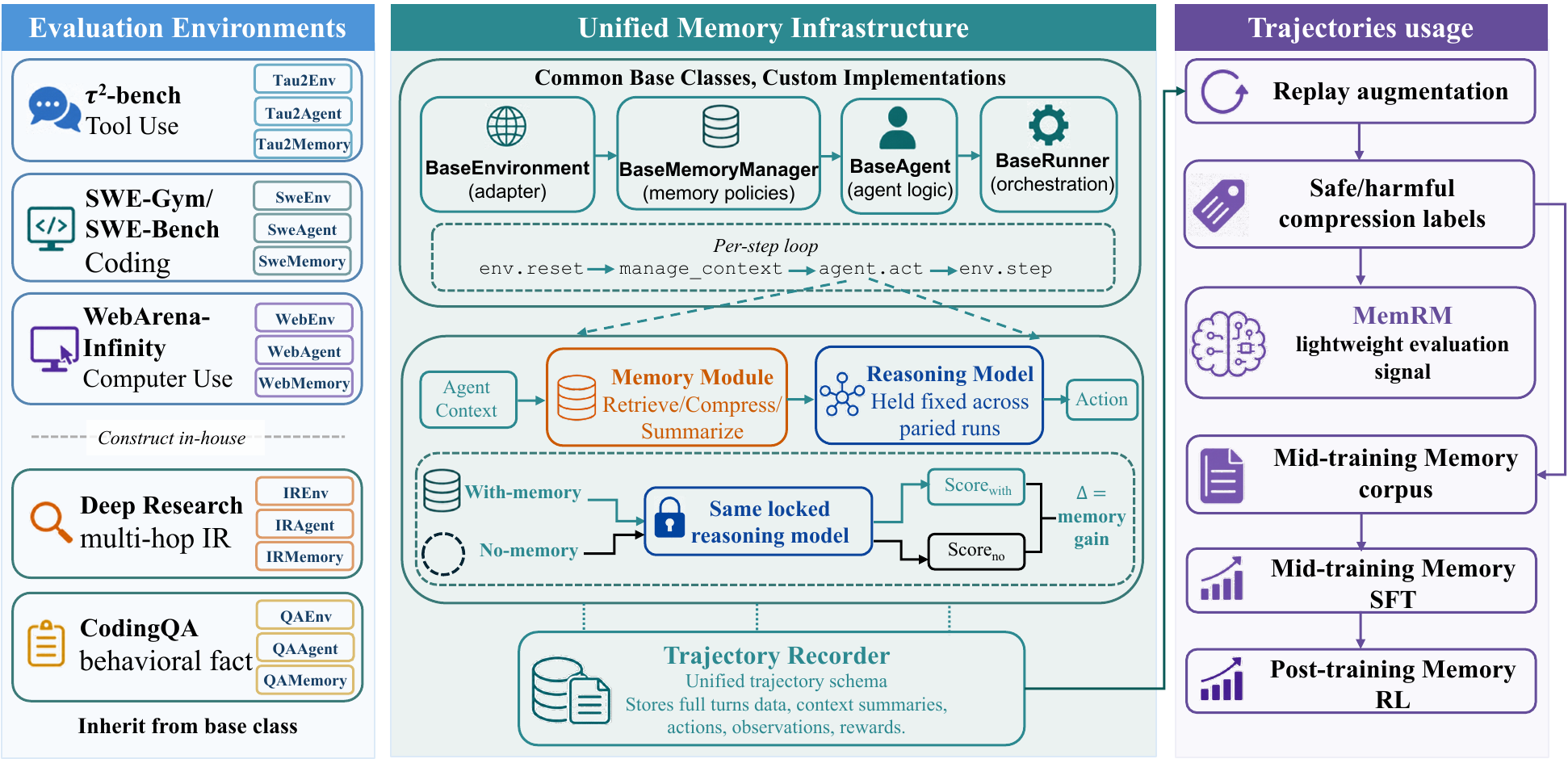
Fast path vs. full rollout. Measuring memory gain the full way takes two paired rollouts per instance — on SWE-Gym that is ≈110 turns and ≈$4.20 of Sonnet 4.5, and a 5-strategy × 3-seed sweep runs $6,300. MemRM replaces each ~10-minute Docker rollout with a sub-second scalar read at 0.985 AUROC.
Leaderboard
Results across all five evaluation tracks. Each row is paired with a same-reasoner,
no-memory baseline (italic, pinned to the bottom of its group) so the Δ column reports
memory-isolated gain, not absolute task performance. This page reads
data/leaderboard.json at load time —
appending a row to that file is all it takes to publish a new result.
Citation
If you use MemGym in your work, please cite:
@misc{xu2026memgym,
title = {MemGym: a Long-Horizon Memory Environment for LLM Agents},
author = {Xu, Wujiang and Wang, Yu and Mei, Kai and Liang, Kaiqu and Wang, Zhenting and Jin, Mingyu and Zhang, Han and Zhang, Shi-Xiong and Hua, Wenyue and Sahu, Sambit and Metaxas, Dimitris N.},
year = {2026},
eprint = {2605.20833},
archivePrefix = {arXiv},
primaryClass = {cs.AI}
}